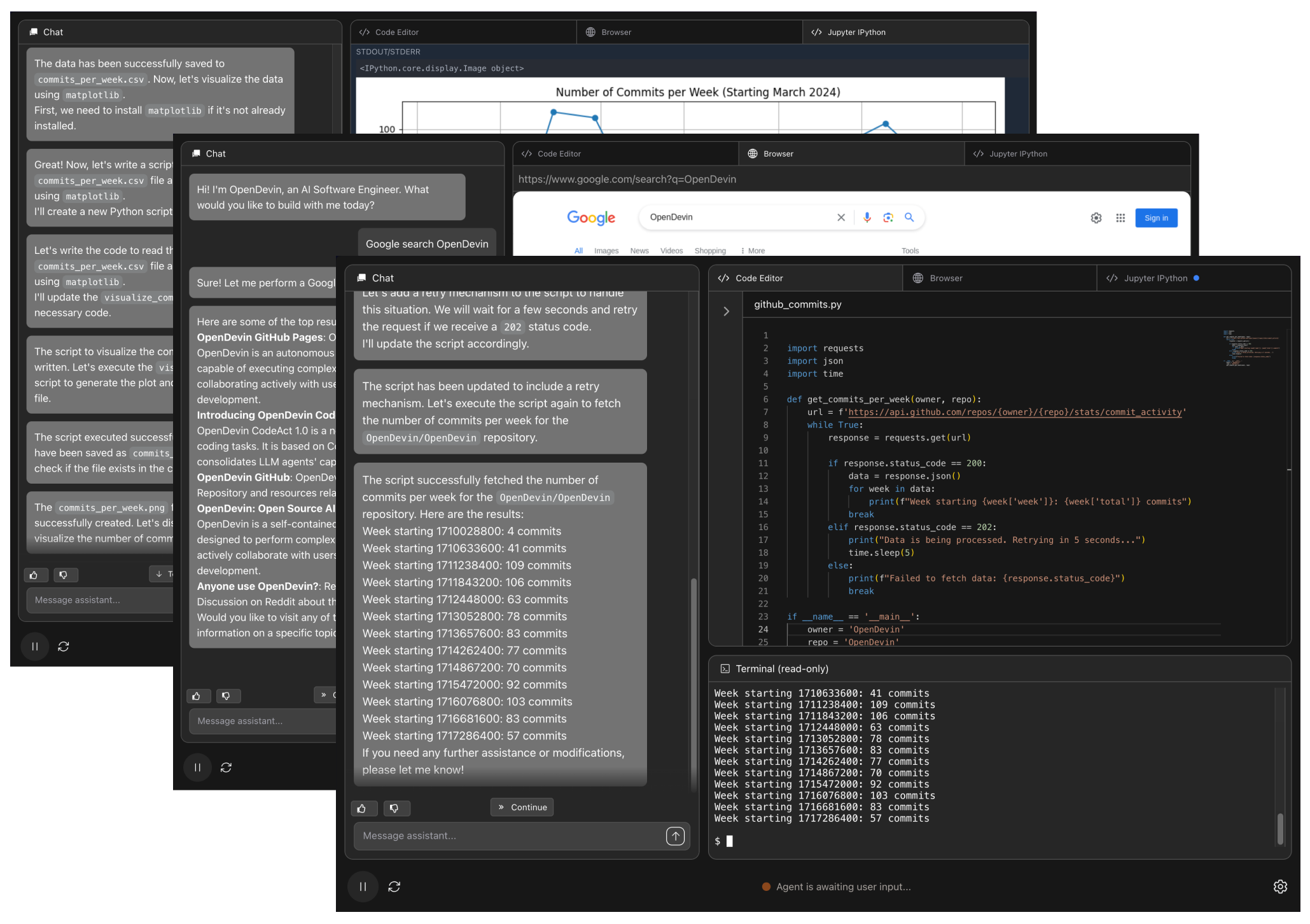
Autonomous Coding Agents
Autonomous Coding Agents
Investigating AI-driven software development with agent harnesses, coding assistants, review loops, and engineering workflows that can operate across real repositories.
Key Findings:
- Claude Code, Codex, OpenCode, OpenHands, Pi, Cursor, Windsurf, and similar harnesses are converging on tool-using developer agents.
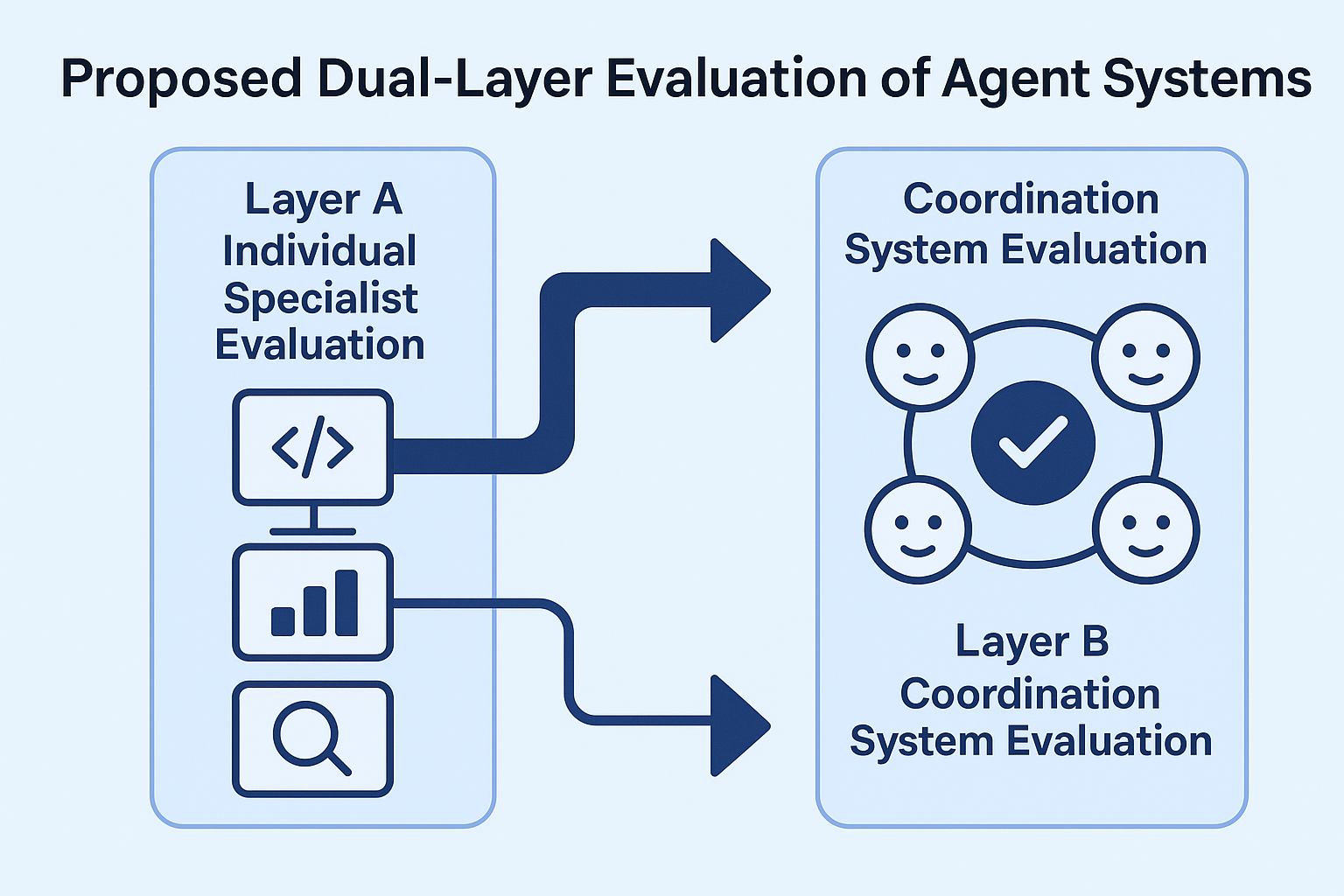
- Effective agentic engineering requires repo-owned rules, repeatable review loops, and explicit handoff paths.
- Agent performance must be evaluated on shipped work quality, recovery, cost, and auditability, not just benchmark task completion.
- The strongest workflows combine human planning and review with autonomous execution inside bounded workspaces.